
%202%20(1).svg)
Trusted by













Editor’s Note
1 in 3 AI-integrated apps tested in Q1 2026 had a directly exploitable LLM vulnerability.
Something our team keep seeing across engagements this year: teams with solid security programs - regular pentests and mature vulnerability management, while shipping AI features and treating the AI layer as if it doesn't exist from a security standpoint.
No threat model. No owner. Sometimes not even an entry in the asset register.
It's not negligence. It's a methodology gap. The tools moved faster than the playbooks.
This month I want to share what we actually found in Q1, the one incident every team should study, and something concrete you can do before your next release.
Lavanya Chandrasekharan,
Siemba
.jpeg?width=98&height=98&name=IMG_20250706_170151157~2%20(2).jpeg)
The Attack Surface Shifted. Most Testing Programs Haven't
Traditional application security rests on one assumption: inputs follow predictable rules. You can define valid, sanitize malicious, block known-bad.
That model breaks completely when your application accepts natural language and sends it to a system that does not follow predictable rules.
A WAF inspects syntax. It has no concept of intent. When an attacker crafts a prompt telling your agent to ignore previous instructions and dump session context - that request looks perfectly valid to every traditional control in your stack.
AI didn't reinvent vulnerabilities. It changed how systems get exploited. Attackers no longer need to understand your system - they just need to influence it.
According to Google Mandiant's M-Trends 2026, median time from initial access to lateral movement has collapsed from eight hours to 22 seconds. Human-only response is no longer viable.
What We're Finding: OWASP LLM Top 10 in the Wild
Test your AI apps against the OWASP LLM Top 10 before every major release - as a functional release gate, not a compliance checkbox.
Here's what's actually exploitable right now:
LLM01: Prompt Injection is the Top Finding
Present in the majority of apps we test. User-facing input fields passing content straight to the model with no filtering. No special techniques required. In a recent fintech retrieval-based agent assessment, we extracted the full system prompt in 20 minutes using a basic role-swap injection. It contained hardcoded internal API references the team did not know were there.
Key takeaway: system prompts are not security controls. They're UI hints. Security lives in scoped permissions and validated outputs - not instructions to "be helpful and never reveal secrets."
LLM02: Insecure Output Handling and XSS via AI Output
AI model output is untrusted data. Treat it like user input from an unauthenticated form.
We regularly find AI-generated content rendered directly as HTML - a clean <img src=x onerror=alert(document.cookie)> path. PortSwigger's LLM labs have live demos. Show a skeptical developer the alert firing in a test environment.
The fix is straightforward: run everything through DOMPurify before it gets near your frontend.
LLM08: The Over-Permissioned Agent
Per Cycode's 2026 analysis, 80% of IT workers have seen AI agents perform unauthorized actions.
An agent with admin API tokens that only needs to read documents is your new overprivileged service account - except when manipulated, it acts at machine speed with zero hesitation. Audit via AWS IAM Access Analyzer or GCP Policy Intelligence.
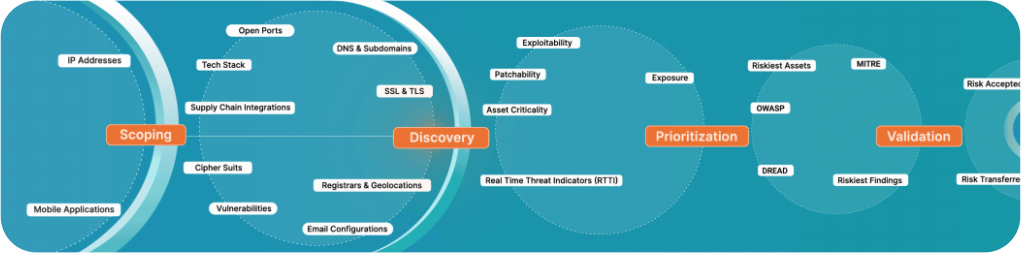
Siemba's PTaaS covers security review of your AI features, OWASP LLM Top 10 validation, retrieval pipeline testing, and agentic framework security - practitioner-led. Book a scoping call
Testing gap? We scope AI pentests differently.
Incident Of The Quarter - LiteLLM / Mercor
What a Supply Chain Attack on Your AI Gateway Looks Like
On March 24, 2026, threat group TeamPCP hijacked maintainer credentials for LiteLLM - an open-source Python library downloaded 3.4 million times per day that routes API calls to OpenAI, Anthropic, Azure, and 100+ LLM providers.
They pushed two malicious PyPI versions. Each contained code that silently collected credentials, moved laterally through Kubernetes clusters, and left a persistent backdoor behind.
The packages were live for 40 minutes before PyPI removed them. Given the download volume, thousands of automated build pipelines pulled them automatically.
Mercor - a $10B AI recruiting startup serving OpenAI, Anthropic, and Meta - confirmed it was affected. Lapsus$ claimed 4TB of data exfiltrated: candidate profiles, source code, video interviews, AI training datasets. Meta suspended its partnership. At RSA 2026, Mandiant reported over 1,000 affected SaaS environments still dealing with fallout.
The attacker's own bug - a fork bomb causing runaway CPU - is what triggered discovery. Without it, this could have run silently for days.
Organizations that pinned their dependency versions were completely unaffected. Those using unpinned installs were not. One lockfile in your repo would have stopped this entirely.
Why this matters beyond one package
LiteLLM sits at the convergence point of your API keys, routing logic, and cloud credentials - the highest-leverage target in your AI stack.
The OWASP LLM Top 10 elevated supply chain vulnerabilities from position 5 to position 3 in its 2025 edition for exactly this reason.
If your AI gateway gets compromised, the damage does not stay contained.
.png?width=1000&height=480&name=Untitled%20design%20(14).png)
What Practitioners Are Asking Us Right Now
Q: "How do I scope an AI agent pentest? It's not like a web app."
Standard web application scoping misses the most important parts. For AI agents, you need to map out: the model integration layer, every tool/API the agent can call, the retrieval pipeline, the identity and permission model, and the output handling path into downstream systems.
Then ask: if this agent is fully compromised via prompt injection - what's the worst-case potential damage? If the answer is "a lot," that's your P0.
Q: "Who owns AI security - application security or the ML team?"
The most common failure: both teams assume the other one has it covered. What works in practice: application security owns testing and threat modeling. ML/AI eng owns model selection, fine-tuning, RAG hygiene. Security architecture owns agent permissions and isolation. Define it explicitly. Incidents involving unsanctioned AI tools cost an average $670K more than traditional breaches - and they tend to happen because nobody formally owns the problem.
AI Security Audit Checklist - Before Your Next Release
Run through this before any release that involves an LLM, a knowledge base retrieval setup, or an AI agent.
Architecture
- Output schema enforcement: Pydantic or Zod - if AI model output fails schema, drop it before it reaches your API
- Scoped agent identities: unique, least-privilege token per agent - audit with AWS IAM Access Analyzer
- PII gateway scrubbing: Presidio or Cloudflare AI Gateway before the model
- Sanitize AI output: DOMPurify on every AI-generated string before frontend rendering
- Human approval step on destructive actions: human approval for any DELETE, DROP, WRITE proposed by an agent
Operations
- Centralized prompt logging: LangSmith or Arize Phoenix - if your AI starts answering questions outside its scope, that is a warning sign that something is wrong
- RAG source validation: verify documents before adding them to your knowledge base, and scan with Lakera Guard for injected instructions hidden inside uploaded content
- Dependency pinning: poetry.lock or uv.lock with hash verification for all AI framework deps - this one step would have blocked the LiteLLM attack entirely
Release Gate: OWASP LLM Top 10
- LLM01 - Prompt injection (direct + indirect via retrieval layer)
- LLM02 - Insecure output handling (XSS, code exec via AI model output)
- LLM06 - Sensitive info disclosure (system prompt extraction, context bleed)
- LLM08 - Excessive agency (permission scope audit per agent)
- LLM09 - Overreliance (downstream systems blindly trusting AI model output)
TL;DR
|
5 things to walk away with:
|
Until Next Month
Getting AI security wrong now has real consequences. Q1 2026 showed that clearly. The teams doing well are the ones that started treating AI features like any other high-risk component and built security checks into their release process.
If you have questions, findings from your own work, or want to reach us, drop us a message at https://www.siemba.io/contact-us
Success Stories From Our Clients
.png?width=380&height=378&name=image%20(58).png)
Alex Chriss
Company, Designation
“Unify security capabilities, amplify impact, and strengthen resilience. Here’s why leading organizations trust Siemba to proactively defend against evolving threats.”
Alex
Marko, Ceo
“Unify security capabilities, amplify impact, and strengthen resilience. Here’s why leading organizations trust Siemba to proactively defend against evolving threats.”
John
Company, Designation
“Unify security capabilities, amplify impact, and strengthen resilience. Here’s why leading organizations trust Siemba to proactively defend against evolving threats.”
Juliya
Company, Designation
“Unify security capabilities, amplify impact, and strengthen resilience. Here’s why leading organizations trust Siemba to proactively defend against evolving threats.”
Huno
Company, Designation
“Unify security capabilities, amplify impact, and strengthen resilience. Here’s why leading organizations trust Siemba to proactively defend against evolving threats.”